-
友情链接:
Powered by 萤石云手机登录入口网页 @2013-2022 RSS地图 HTML地图

如果你用一个人能听懂的语言跟他说话,那就会进入他的头脑。如果你用他的语言跟他说话,那就会进入他的内心。——纳尔逊·曼德拉
解释大脑如何工作以及如何处理语言是神经科学的主要目标之一。人类语言处理由大脑中的语言网络 (LN)支持,语言网络是大脑中的一组左侧额颞叶区域。LN 对语言输入有很强的选择性反应,研究人员也试图使用大型语言模型 (LLM)来研究它。LLM 经过训练可以预测序列中的下一个标记,并且似乎可以捕捉人类对语言反应的某些方面。
鉴于这些有趣的相似之处,仍然存在一些悬而未决的问题:
是什么推动了未经训练的模型中的大脑协调?
模型-大脑对齐是否与形式(语法、组合性)或 v 能力(世界知识、推理)相关?
如何解释这种一致性:是训练规模还是训练类型?
本文讨论了一些试图回答这些问题的最新文章。
先前的研究表明,某些人工神经网络的内部表征与大脑中的表征相似。
换句话说,先前的研究表明,大脑处理语言的方式(大脑中的激活)和神经网络模式处理语言的方式之间存在相似的模式。这些研究通常通过功能性 MRI观察大脑中的激活模式并观察神经网络中的激活(尤其是 LLM)来进行。
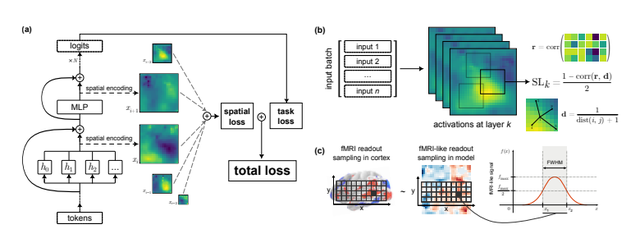
首先,我们发现只需要 2% 的监督更新(时期和图像)就能实现与成人腹侧流约 80% 的匹配。其次,通过改善突触连接的随机分布,我们发现 54% 的大脑匹配“在出生时”就可以实现(即完全不需要训练)。第三,我们发现,通过仅训练约 5% 的模型突触,我们仍然可以实现与腹侧流近 80% 的匹配。——来源
总的来说,这些发现表明,卷积网络中的架构偏差使得皮质视觉表征的许多方面在突触连接通过经验进行调整之前就能够轻易地出现。——来源
令人惊讶的是,这种对齐不需要太多训练,也不需要太多的迭代次数。这可以通过架构的选择来解释(例如,卷积网络的归纳偏差部分模仿了人类处理图像的方式)。换句话说,选择适合该任务的神经架构将模仿动物的进化过程,即“出生时”,动物就具有视觉能力,并且这个过程通过学习得到改进。
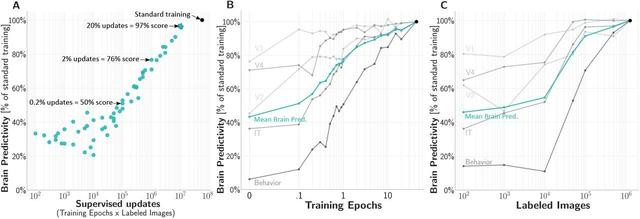
只需少量监督更新(对数 x 轴)即可实现较高的大脑预测率。来源
因此架构的选择很重要。例如,所选的优化函数存在偏差,会影响泛化能力。

这就引出了一个问题:架构有多重要,训练有多重要?
在这项研究中,作者使用一系列神经影像数据集(记录人们对听觉或视觉刺激的反应)来对图像做出反应。
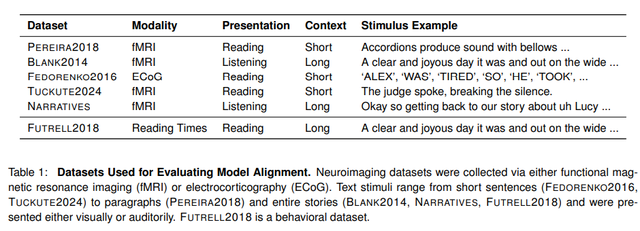
对齐通常是通过预测大脑内部表征中的神经活动来实现的,使用提供给人类参与者和模型的相同语言线索。本文的作者使用了不同大小的模型(14M、70M、160M、410M、1B、1.4B、2.8B、6.9B),还使用了各种检查点(从未训练的模型到预训练的模型)
为了使对齐有意义,模型必须能够针对随机标记和语言输入表现出不同的行为。未经训练的模型(尽管远不如经过训练的模型)仍然可以实现相对不错的对齐,并且优于针对随机标记进行对齐评估的模型。
但这种令人惊讶的排列顺序的原因是什么呢?
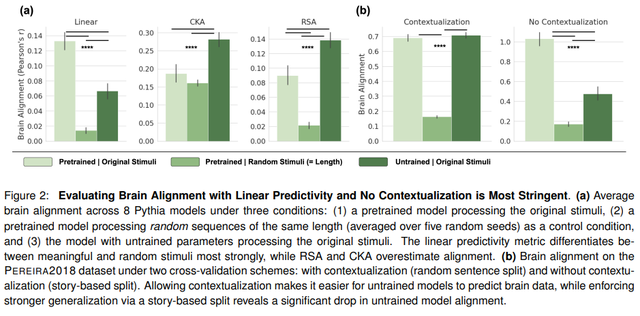
作者尝试调查可能有哪些因素。结果显示:
为序列设计的模型(GRU、LSTM、TRANSFORMERS)比线性或 MLP 等模型具有更高的大脑对齐度。换句话说,上下文和时间整合的使用会影响对齐。与旋转位置编码相比,使用静态位置嵌入在对齐方面更具优势,因为它可以捕捉句子中的内在时间动态。
通过消融,注意力机制和位置编码成为 Transformer 对齐中最重要的组成部分。
对齐是由形式而非功能性语言能力驱动的。语言能力涉及对语言规则和模式的了解,而功能性语言能力涉及使用语言来解释和与世界互动。模型的初始化方式也会对对齐产生影响。
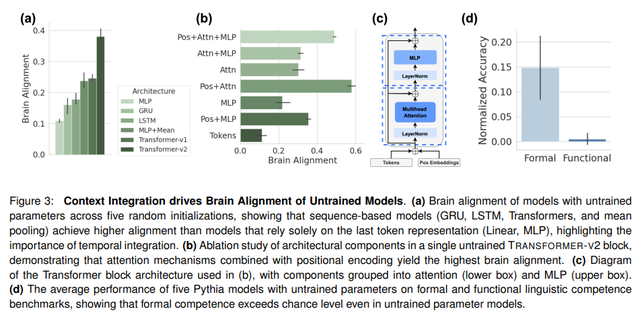
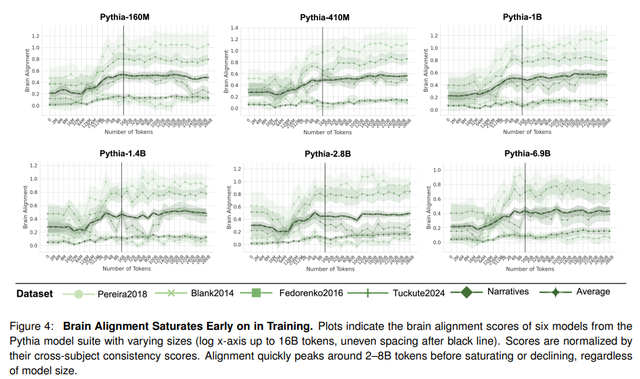
一旦作者确定了未经训练的模型为何已经部分与大脑对齐,他们就会调查训练过程中发生的情况。为此,他们使用Pythia之类的模型,其中每个模型都有不同的维度和检查点。大脑对齐与未经训练的模型相似,直到大约 128M 个 token。然后出现急剧增加(约 8B 个 token),然后在训练的剩余部分达到饱和。
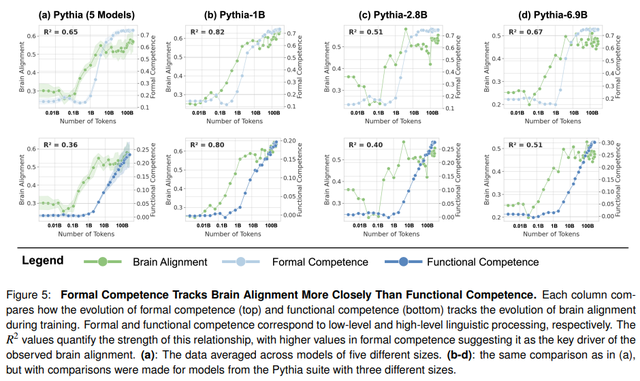
作者研究了正式和功能性语言能力在训练过程中如何发展。有趣的是,正式能力与对齐最相关
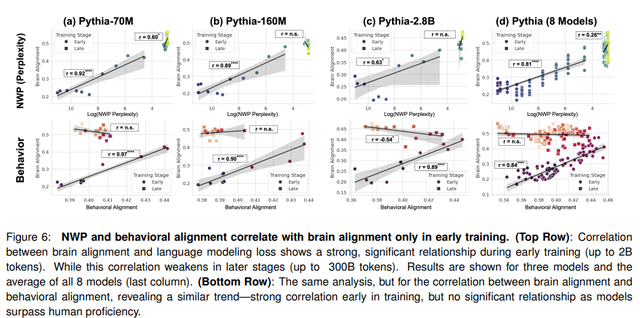
人类会预测性地处理语言,读出意想不到的单词需要更长的时间。这种行为在 LLM 的初始训练阶段有所体现,但当它们达到熟练程度时,人类开始编码与人类直觉不同的统计规律。此时,对齐也会减少,这表明更强大的模型依赖于与人类语言理解基础不同的机制。对齐结果表明,在早期训练期间,模型与人类处理一致,而语言机制在后期出现分歧
我们证明,与人类语言网络 (LN) 的匹配主要与形式语言能力相关,在训练早期达到顶峰并达到饱和。相比之下,涉及世界知识和推理的功能性语言能力在此阶段之后继续增长。 —来源
与之前的文献一致,这项研究表明,在训练的第一阶段,模型首先学习语言规则(例如语法和句法),然后出现语言能力和推理等后续过程。在训练的第一阶段,大脑活动和模型之间的一致性开始出现,尤其是在形式语言学上,直到达到峰值然后达到饱和。有趣的是,即使是未经训练的模型也表现出基本的一致性。这是从架构选择(归纳偏差、标记集成机制和训练动态)中得出的。这也意味着不同的选择可能会在未来带来更好的一致性。
另一方面,在训练的后期阶段(尤其是对于大型模型),LLM 与人类大脑活动之间的差异开始显现。当模型达到较高的语言熟练程度时,模型开始编码与预期不同的模式。一方面,这为开发可能与人类大脑更相似的架构开辟了有趣的前景。另一方面,这意味着模型无法完全匹配人类大脑的语言处理能力。
Powered by 萤石云手机登录入口网页 @2013-2022 RSS地图 HTML地图